
Identify and prevent data quality failures at build time and during runtime with automated checks that keep data accurate, fresh, and consistent.








Quality checks run automatically in every pull request so code changes meet your standards before they reach production.
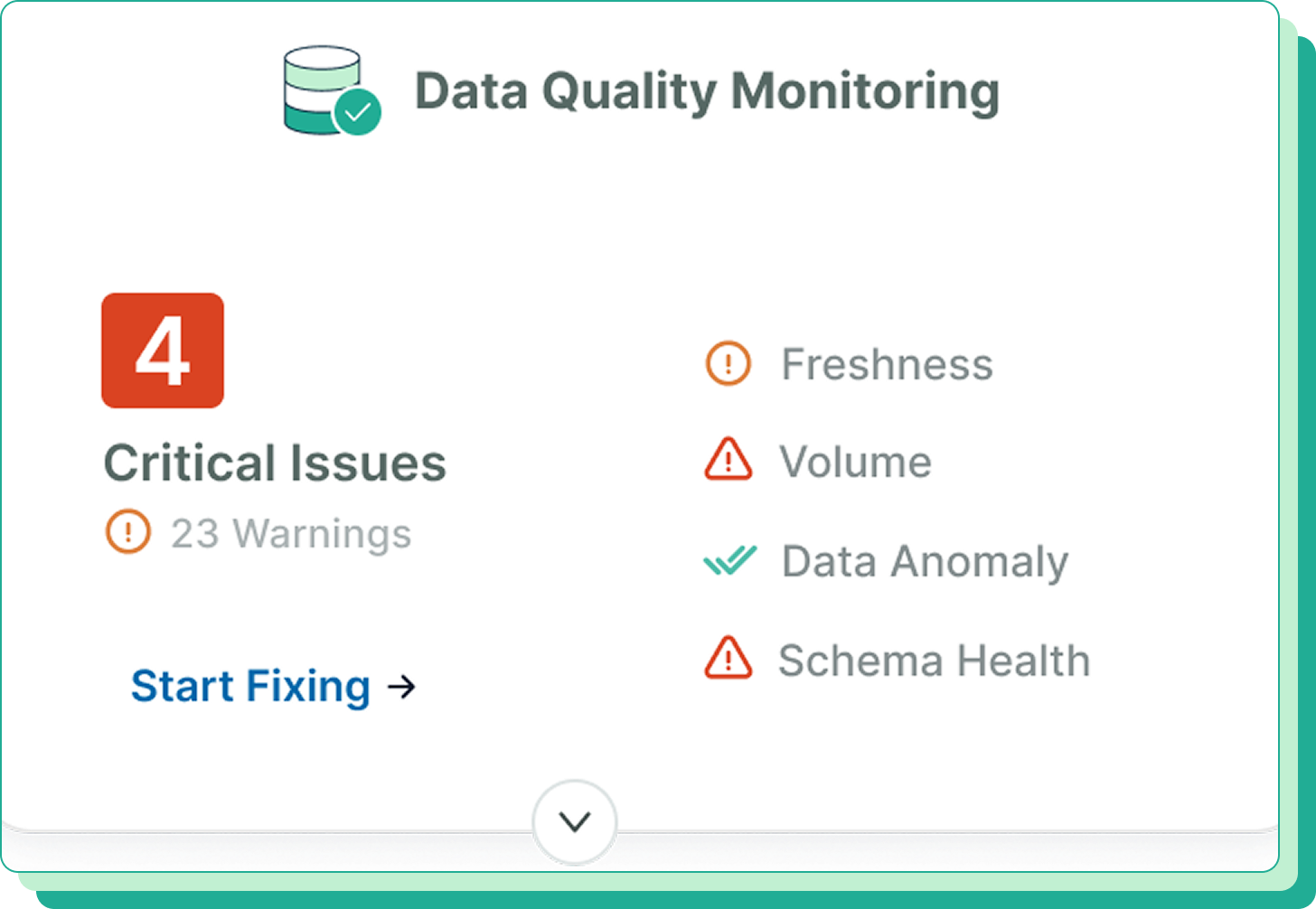
Quality validation happens automatically in your workflow so issues are caught early and resolved before users feel the impact.
Validate changes in every pull request to ensure code meets standards before release.
Run schema checks, rule based validation, and anomaly detection as part of the development cycle.
Track SLAs, visualize quality trends, and surface recurring issues automatically.
Use data contracts to standardize expectations across pipelines and teams.
Catch schema changes early, surface defects before they ship, guide new engineers, and keep trust high across analytics and AI.
Stop column changes, null shifts, or type mismatches from breaking downstream analytics.
Find issues earlier in the development process before they become production defects.
Give new engineers confidence by surfacing quality expectations directly in PRs.
Ensure data entering dashboards and models meets known standards every time.




Give every team the confidence that their data is accurate, fresh, and reliable with automated checks that run continuously.
Foundational is a new way of building and managing data: We make it easy for everyone in the organization to understand, communicate, and create code for data.

Foundational detects changes to tables, models, or logic, then runs quality checks automatically in the pull request. Schema rules, business logic, and thresholds are evaluated before merge so invalid updates never reach production.
Data quality depends on understanding how data moves and transforms across systems. By using data lineage to trace dependencies and transformations, teams can identify where quality issues originate, understand downstream impact, and prevent errors from propagating across the data stack.
Schema checks identify missing fields, renamed fields, modified types, or structural changes that could break downstream pipelines or dashboards. These checks adapt to your warehouse or transformation layer.
Foundational quality checks run automatically in GitHub, GitLab, and major CI and CD platforms. Engineers get immediate feedback inside the tools they already use, with no separate interface to learn or manage.
No. Validation relies on metadata, schema definitions, rule configurations, and expected value patterns. No raw data is stored or accessed, making the approach secure and compliant.
Foundational can be set up in less than an hour, by authenticating us to the relevant GitHub repositories and to any BI tools. No code changes or integration work are needed.
