
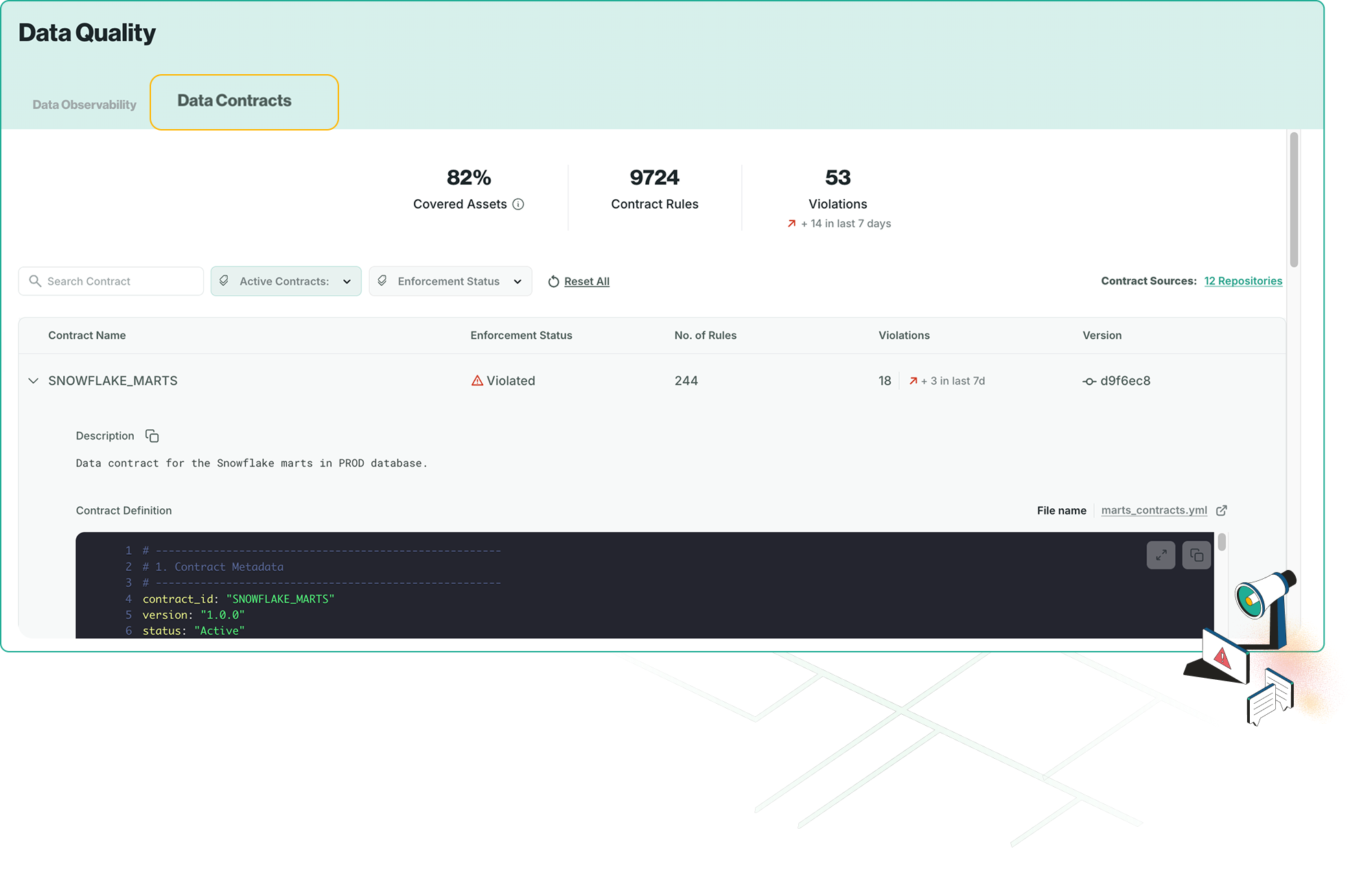
Create contracts that keep data stable, schemas consistent, and quality rules enforced before code reaches production.







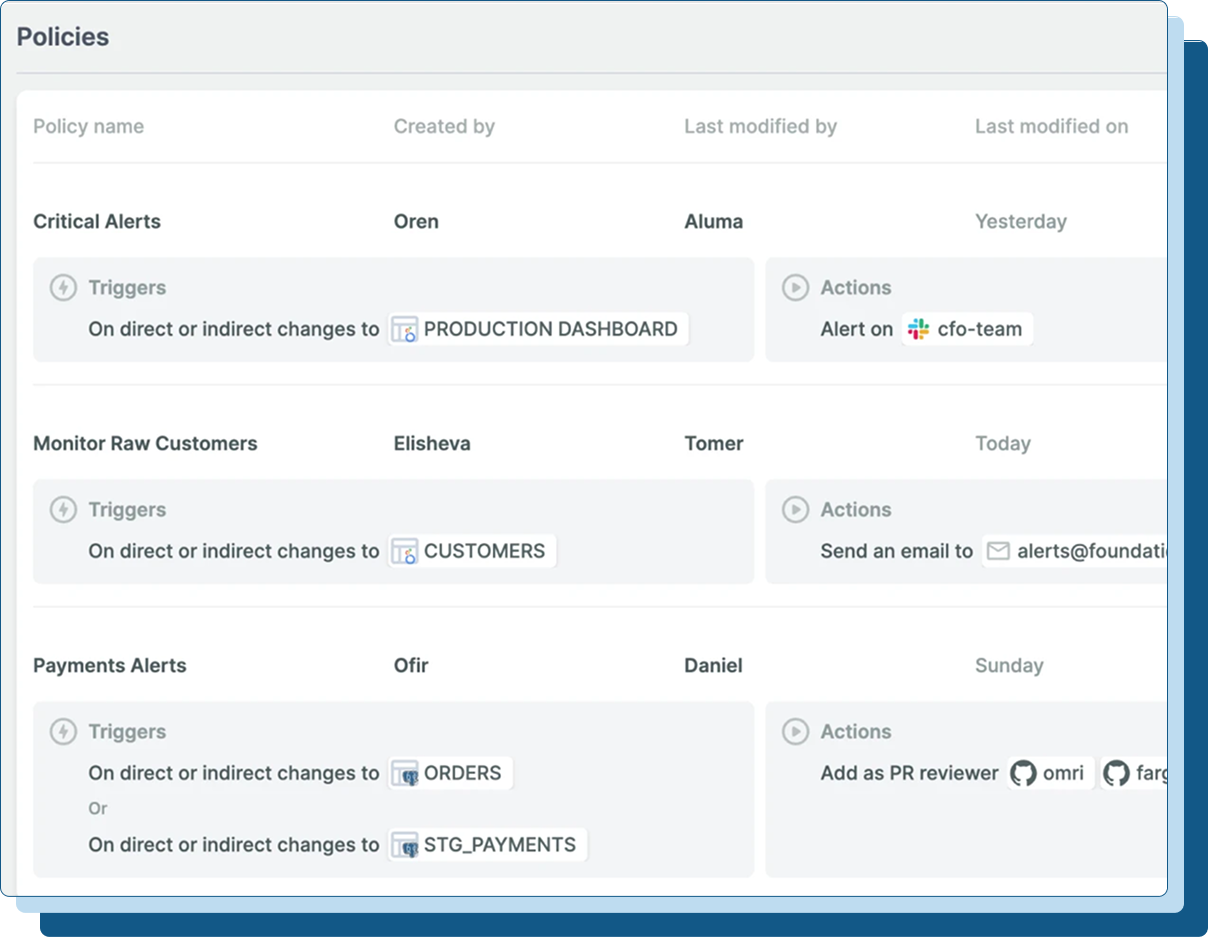
Create automated rules and custom policies to keep everyone aligned around data changes - from producers, to consumers and stakeholders.
Contracts make standards enforceable and consistent across teams, tools, and development workflows.
Detect column additions, removals, or type changes automatically.
Set rules such as required fields, allowable value ranges, and key uniqueness.
Manage contracts in Git for full transparency, review, and auditability.
Block invalid merges or require approvals for exceptions in existing build pipelines.
Surface issues during build time, accelerate reviews with precise impact insight, evolve schemas with confidence, and ensure teams stay aligned through automated notifications.
Enforce data quality rules continuously across build time and run time so issues are surfaced before they impact production.
Give reviewers exact visibility into which fields, tables, and downstream assets are touched by each change.
Change models confidently with full visibility into affected dashboards and reports.
Bring owners into the review process automatically with impact based notifications.




Prevent schema drift, ensure consistency, and stop bad data before it reaches production.
Foundational is a new way of building and managing data: We make it easy for everyone in the organization to understand, communicate, and create code for data.

Data contracts prevent schema drift, inconsistent logic, and unexpected breaking changes across pipelines. They define structure and rules up front so quality is enforced during development rather than after issues reach production.
Data contracts define expectations between data producers and consumers, including schemas, ownership, and SLAs. Data lineage provides the context needed to apply data contracts across systems by showing how data flows between producers, transformations, and downstream consumers.
The validation engine runs checks automatically on every pull request, commit, or scheduled build. When a change violates a contract, the update is flagged and fails validation, ensuring issues are resolved before merge.
We detect schema changes and semantic issues through code analysis before the code is merged, allowing us to flag violations, whether explicitly defined by a contract, or implied by existing dependencies.
We currently focus on changes to schema and data freshness, which can all be evaluated from code and metadata. Foundational doesn’t access the data itself.
Contracts document expectations for every field and validate rules automatically. This creates a clear audit trail and ensures data quality rules are enforced consistently across all pipelines.
