
Unmatched and comprehensive cross-platform lineage across your data stack created automatically from the source code that defines your pipelines, transformations, and analytics.








Traditional lineage solutions are typically limited to queries and logs, creating lag and inaccuracies. Analyzing the source code, as the source of truth, introduces better coverage, lag, and accuracy. Learn what data lineage is and how modern data lineage platforms generate accurate, code based lineage across the data stack.
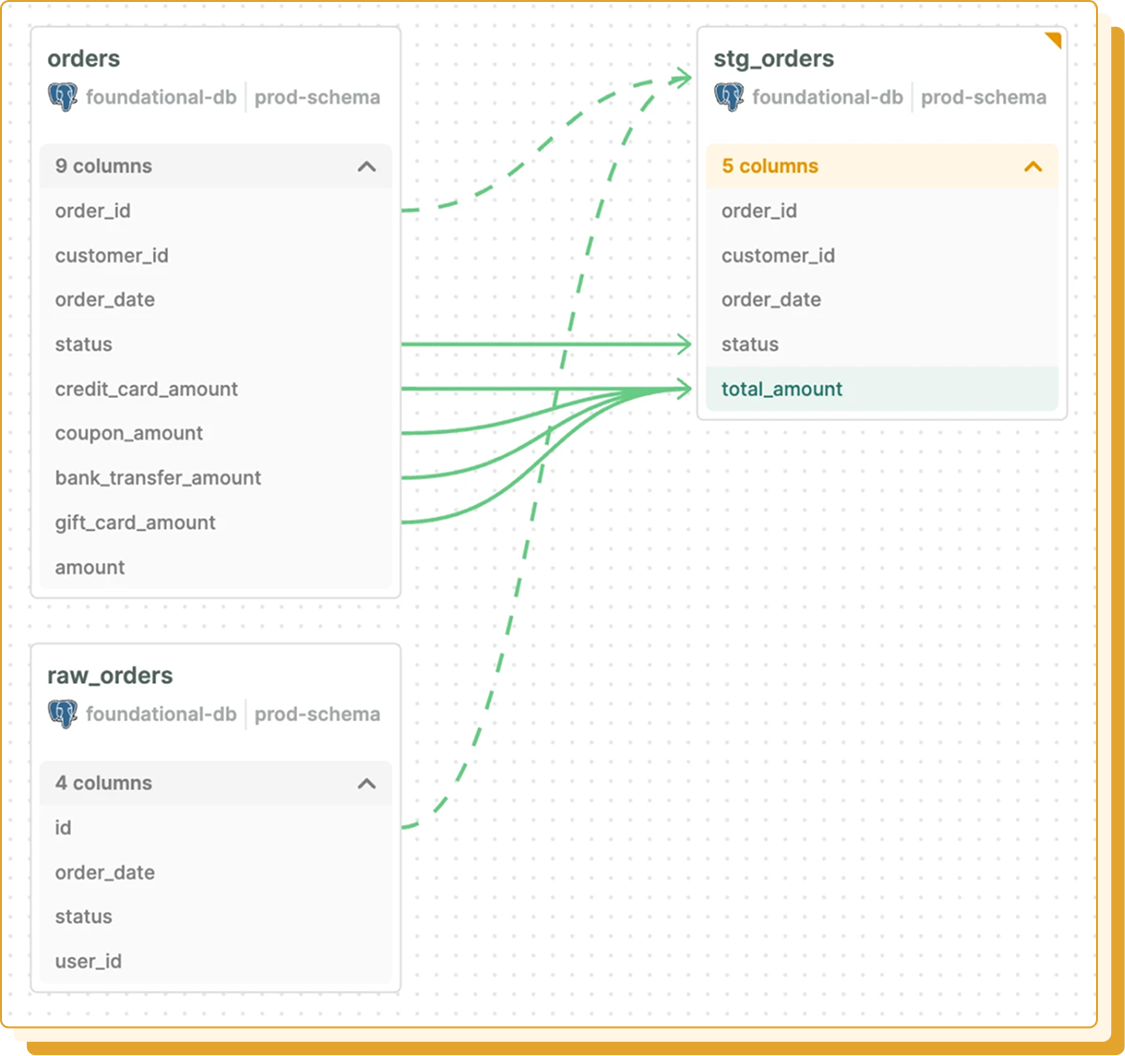
Ensure your engineering and governance teams always have accurate, actionable lineage without manual upkeep.
Map transformations, joins, and aggregations from field to field with unmatched depth.
Connect sources, pipelines, warehouses, and BI tools to view the full data journey.
Lineage updates automatically on every commit so teams never rely on stale diagrams.
Find any field, understand its context, and answer where it comes from or how it is used.
Teams rely on lineage to move faster, reduce risk, and improve the reliability of analytics and operations.
Surface the exact transformation or code change responsible for a break, even within extensive and highly distributed data systems.
See every downstream dependency before making a change.
Generate audit ready reports showing exactly what changed and how it impacts critical data assets.
Give new team members a clear understanding of how data flows across systems.




End the guesswork with lineage that provides complete visibility and context into how changes affect your data.
Foundational is a new way of building and managing data: We make it easy for everyone in the organization to understand, communicate, and create code for data.

Foundational supports SQL, Python, and Scala. We specialize in analyzing common data development frameworks such as dbt, Spark, Airflow, SQLAlchemy, and many others. Ask us to learn more.
We support GitHub, GitLab, Bitbucket, and Azure DevOps
Foundational does not access or process any data or PII. We only access code and metadata.
Yes, Foundational can also parse warehouse logs to analyze the dependencies of notebooks, ad-hoc queries, views, and others.
Foundational can be set up in less than an hour, by authenticating us to the relevant GitHub repositories and to any BI tools. No code changes or integration work are needed.
Foundational creates cross-platform lineage directly from source code analysis across SQL, Python, Java, dbt, Spark, and the ORMs and AI pipelines that move data through your stack. Because it is derived from the code itself rather than inferred from query patterns, the lineage is deterministic and reproducible across every system it touches, from source applications through pipelines to BI dashboards.
