
Most lineage tools start at the warehouse. Foundational analyzes the Java, Python, and C# application code and operational databases where your data actually originates, automatically mapping the complete logic before it ever reaches Snowflake or BigQuery.
Request a DemoTraditional data catalogs only see what’s already landed in Snowflake or BigQuery. But the real context exists in your application code. It's the logic that defines a website entry, calculates attribution, or masks PII. Foundational bridges this gap by parsing the engineering side of your data stack, ensuring that downstream visibility includes upstream intent.
We parse application code across Java, Python, Scala, and C# to extract lineage at the source, before data moves anywhere. No query logs. No manual mapping. No blind spots from unexecuted code paths.
Your product databases contain logic your catalog has never seen. Foundational maps lineage through operational systems alongside your warehouse, so you understand how application behavior shapes every downstream metric.
Spark jobs, Airflow DAGs, Python pipelines, and ORM-driven writes all contribute to your data. We parse each one and stitch them into a single, unified lineage graph alongside your SQL transformations.
Identify sensitive fields as they flow through application code, pipelines, and BI, before a breach or audit forces the question. Foundational surfaces PII and PHI at the column level across every system it covers.
Trace every column from its origin in application code to its destination in your BI layer. Understand exactly how fields are created, joined, filtered, and transformed across every system in your stack.
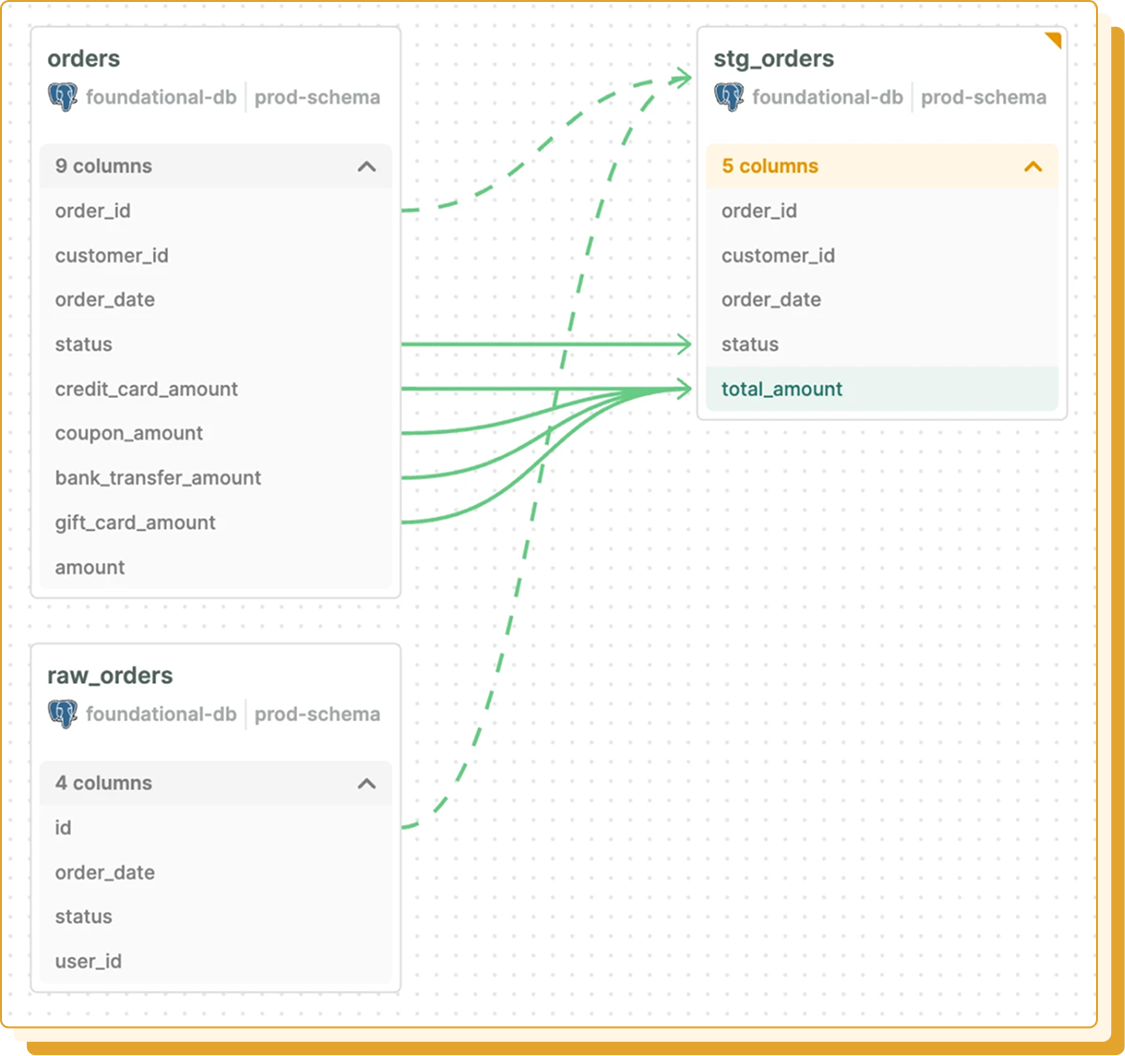

Foundational stitches lineage across your entire stack, connecting application code, operational databases, transformation pipelines, and BI tools into one unified view. No gaps between systems. No separate tools for separate layers.
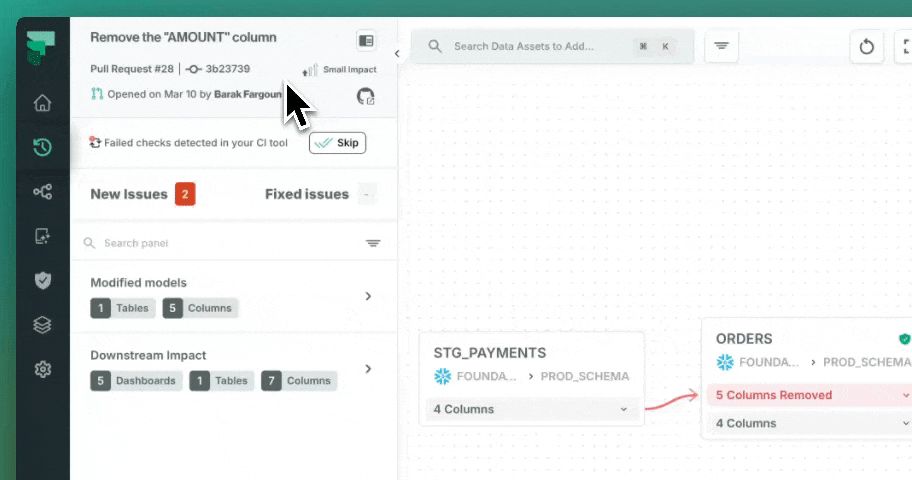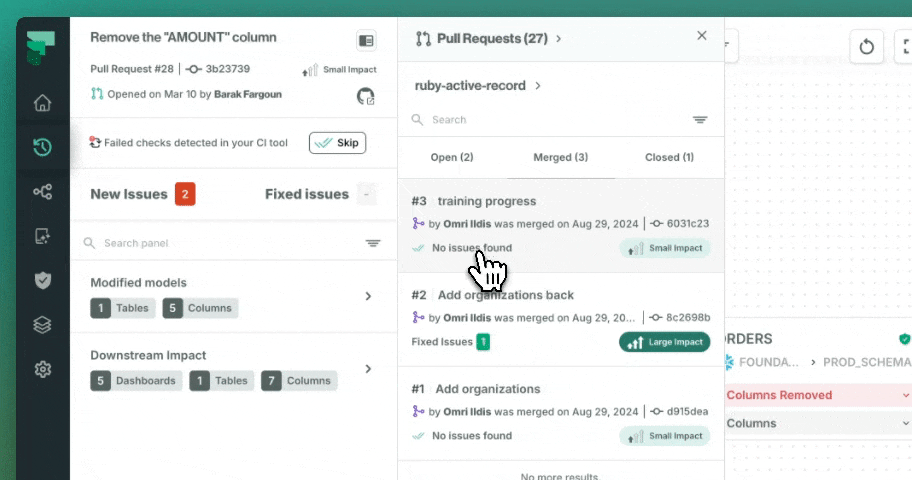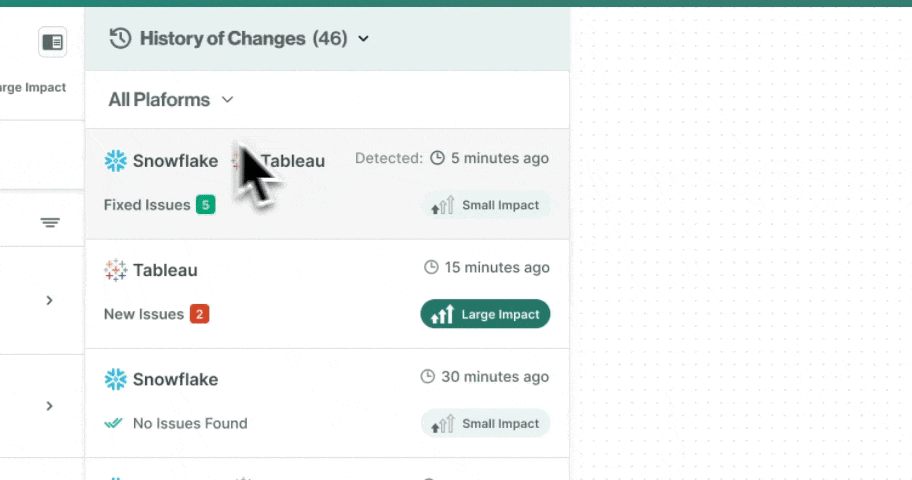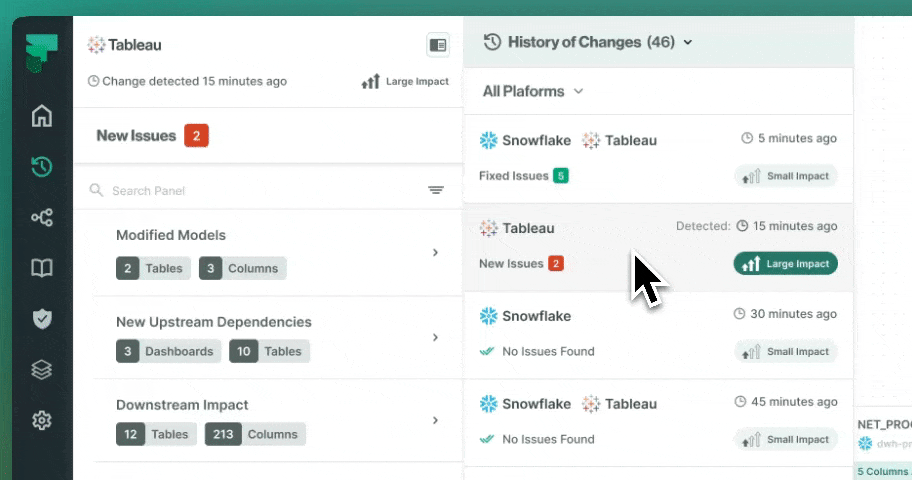
Every pull request is analyzed automatically. Before a single line merges, your team sees which downstream models, dashboards, and pipelines are affected, with severity scoring and owner notifications built in.
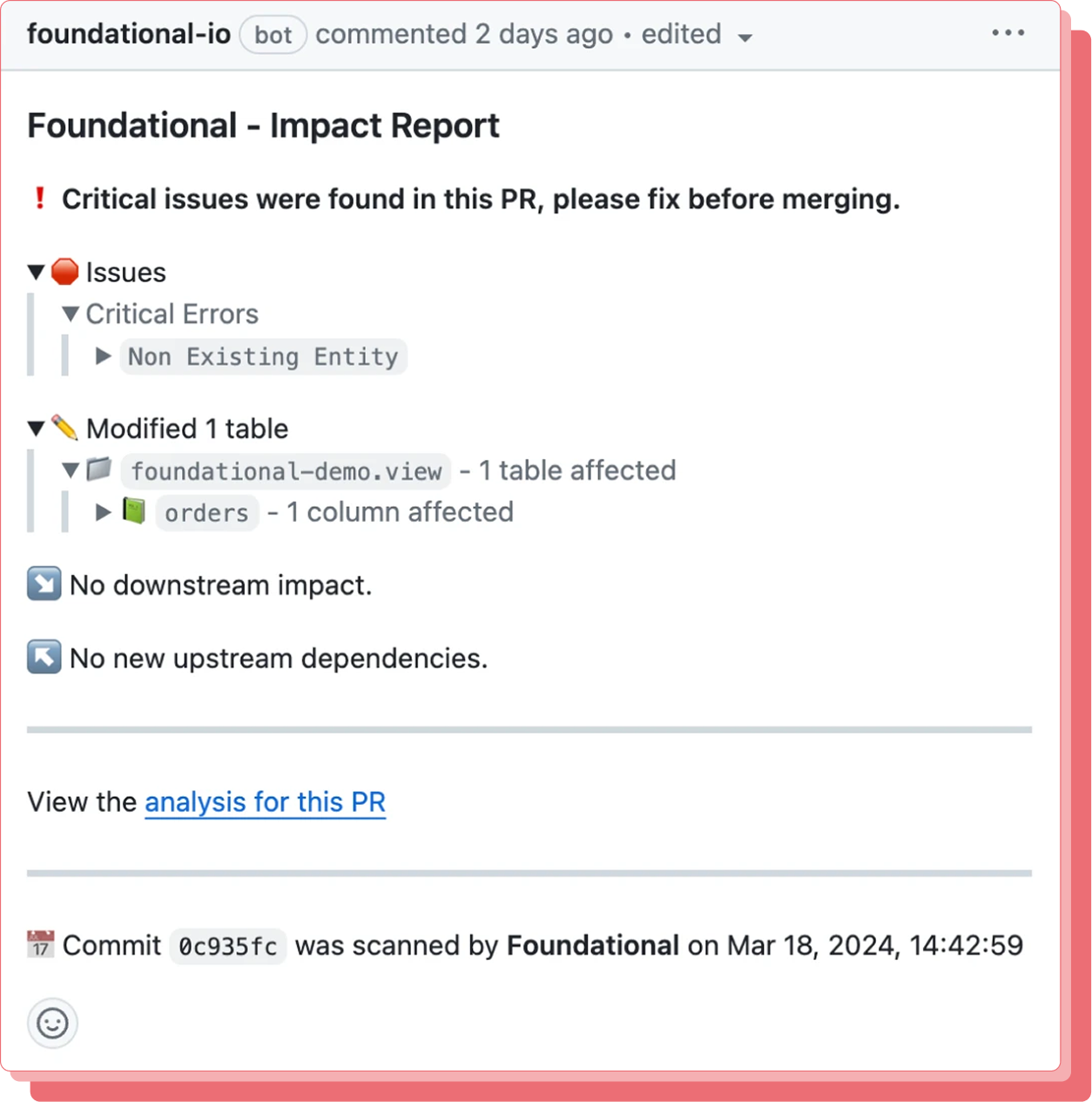
Traditional catalogs collect metadata from query logs. That means anything written in application code, executed through an ORM, or processed in a Spark job stays invisible. Foundational analyzes the source code itself, giving your team complete lineage coverage from the first line of application logic to the final number in your executive dashboard.


Reduction in data incidents.
Manual mapping required.
Stack coverage from app layer to BI.
Request a demo and we will show you exactly what Foundational surfaces across your application layer, operational databases, and downstream BI in a live walkthrough of your stack.
