Table of Content
Subscribe to our Newsletter
Get the latest from our team delivered to your inbox
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Ready to get started?
Try It Free


In the age of data products and data becoming mission-critical, automated data management is becoming a necessity. DataOps, or Data Operations, is a new(ish) discipline that combines, as the name suggests, data management and operations. With data ecosystems greatly maturing and increasing in complexity, many data teams find themselves in a state of constant firefighting, experiencing data incidents and poor data governance, while not being able to move from reactive to proactive, when it comes to the data stack.
In this article we’ll review the main principles of DataOps and data management and suggest solutions that data organizations can adopt. Some of these may even seem naive – but the situation today is that many data organizations are sometimes lacking even the basic capabilities and key know-hows.
Data management is a broad term that describes the practice of collecting, storing, organizing, and maintaining data within an organization. While some definitions consider modeling and integration, the main pillars of data management are data governance, data quality, and often security and privacy. All of these should be in place to ultimately ensure that data is consistent and valuable for decision-making.
Today, with tools such as Snowflake, Fivetran, and dbt, it is very easy to build out a data stack, establish ingestion and some modeling, which with some business intelligence work can also publish data to be consumed by the business. On a smaller scale this works well and there’s no real need for data management, even though some of these tools do offer some native capabilities to do things like source control and versioning, or setting up access controls.
However, once this system scales up - the data warehouse goes to hundreds of tables instead of a few dozens, dbt grows to a hundred models and your easy-to-set-up BI tool now has dozens or even hundreds of dashboards (including those personal ones!) – things get messy. That’s where we need data management – and of course, automated is better.
The following are the key components of implementing data management, covering both the technical and process aspects:
An underlying pillar of data management is having the ability to manage changes, which means to be able to understand, validate and review every change that happens around data. Modern tools and frameworks such as dbt and Airflow natively support this, allowing data organizations to properly stage, test and review every code change that goes into the data platform. Faulty code changes can be reverted, and changes can be tracked and documented against their owner for future reference.
This is typically available by the data warehouse, allowing admins to determine what can be accessed and by whom. Access controls is a key component of any governance program and as such, falls into our definition of data management as well.
This may sound trivial, but as the data ecosystem dramatically evolved in the past few years, a code review process – being standard in the software industry – is not necessarily the norm. Outside of having the process in place, due to the fragmented nature of the data ecosystem, having enough context to thoroughly understand the implications of a code change and run a code review – is hard. In the data stack, a small, one-line code change that modified the name of a field, may have meaningful implications.
Similarly to code reviews, while CI/CD is standard in software development, in data that is not always the case. Having proper CI/CD that checks and validates code changes including their full implications on data at the time of build is critical for appropriate data management. Here there is also an organizational challenge, as the data organization may not share the same CI/CD resources with the software engineering teams, resulting in an isolated environment, which may not benefit from the latest updates and maintenance happening on the software engineering side.
Despite all the data management processes being in place, unintended issues might still occur. These warrants having live monitoring in place, checking things like schemas and data freshness to ensure that changes are not introducing damage.

There are a lot of these. But in this article, we’ll name a few key ingredients that make it hard for organizations to implement scalable data management today:
A lot of data tools today are still not managed properly in version control. Ironically, this is especially true for the tools that publish data, such as business intelligence, and tools that ingest data such as ETL. While some tools have introduced support for this, it is very rare to see a BI tool that is managed in git and as such, every change that is being made is happening “behind the scenes”, without any sort of documentation, peer review, or auditing process.
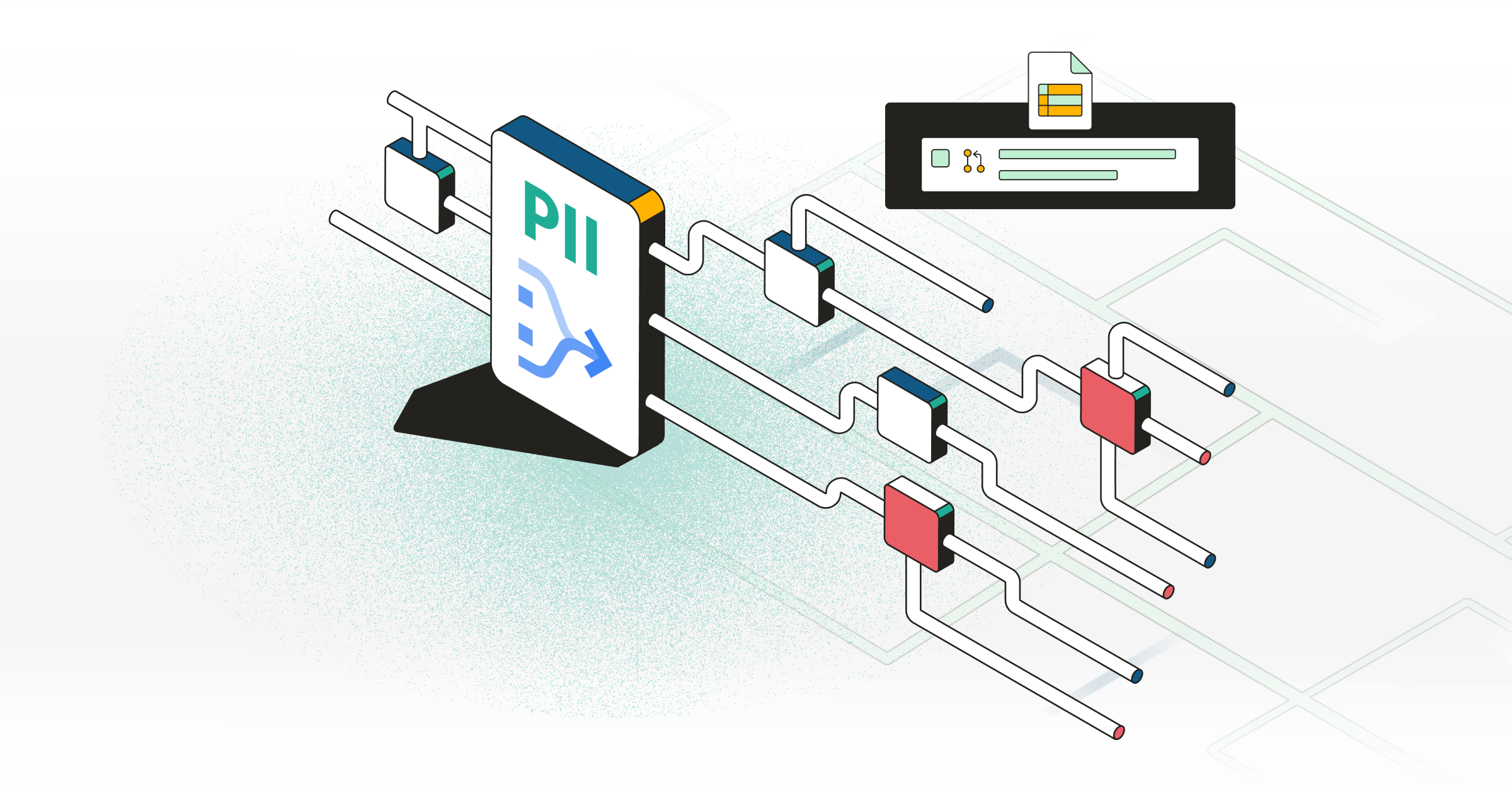
Due to the (technical) nature of managing code at scale, different repositories that touch data are owned by entirely different teams. Engineering owns the production of data and typically some parts of ingestion as well, while data owns the downstream - the data warehouse and the BI tool. As a result, a lot of processes typically do not cover the entire data flow, for example, code reviews are not done across the entire set of repositories, and the same for CI testing. Data lineage tools would mainly address the data warehouse and consequently, the entire upstream portion of the data flow is often lacking, undocumented, and unmonitored.
Teams that do not have visibility cannot communicate, and a direct byproduct of this lack of visibility is different teams not talking to each other when making changes that have a cross-functional impact. This sets the reality for data incidents, and this somewhat explains why they are so common.
The modern data ecosystem has a lot of tools for infrastructure, applications, and reporting. As a result, applying data management across a large set of tools is hard - both from a technical standpoint as well as an operational one. Tools are constantly evolving and data management tools have to be integrated, which creates a meaningful burden on the teams that attempt to implement them.

At Foundational, we took a unique approach to data management by integrating directly with source code, across all the repositories that are relevant to data throughout the business. By natively integrating with git, the effort of adopting a new tool is minimized, and ensuring coverage is straightforward.
Foundational checks and validates every code change throughout all the different repositories and stakeholders in the business, covering engineering changes happening upstream, as well as changes in models and pipelines running on the warehouse. The goal is to unify data management across every function that may process or modify data. And as a bonus, since we analyze code, many of the issues that are often introduced to production, whether it’s data quality, privacy, or even cloud cost issues, can be addressed and in most cases, completely avoided.
Our goal is to streamline data development across the entire company, helping engineering and data teams deploy changes faster and with greater confidence – Chat with us to see a demo.